|
I am a third-year Computer Science Ph.D. student at Stanford University, advised by Chelsea Finn and Percy Liang. I conduct research in NLP, robotics, and machine learning. I currently work on LLM post-training for Marin (Stanford’s open-source foundation model project led by Percy Liang), focusing on synthetic data and distillation for reasoning. Previously, I built OpenVLA, an open-source vision-language-action model that became the #1 most downloaded robotics model on Hugging Face (14.7M+ downloads, 6.1K stars, 727 forks). I also developed post-training techniques for VLAs and video diffusion transformers which produced state-of-the-art robot policies with strong community adoption: OpenVLA-OFT (235K+ downloads, 1.2K stars) and Cosmos Policy (30K+ downloads, 753 stars). Before my Ph.D. studies, I graduated summa cum laude from UCLA with a B.S. in Computer Science. I also received an M.S. in Computer Science from Stanford, where I was one of five students in my graduating class supported by the Siebel Scholarship. Google Scholar / Twitter / LinkedIn / GitHub |

|
Research Projects |
|
|
Cosmos Policy: Fine-Tuning Video Models for Visuomotor Control and Planning
Moo Jin Kim, Yihuai Gao, Tsung-Yi Lin, Yen-Chen Lin, Yunhao Ge, Grace Lam, Percy Liang, Shuran Song, Ming-Yu Liu, Chelsea Finn, Jinwei Gu ICLR 2026 (Top 2% of submissions by reviewer score) project website / arXiv / code / models & data We present a straightforward method for converting a latent video diffusion model into a robotic control system. Our approach generates robot actions as latent frames within the video model's diffusion process while also producing predicted future states and value estimates for model-based planning. We achieve state-of-the-art performance on simulation benchmarks (98.5% SR on LIBERO, 67.1% SR on RoboCasa) and surpass diffusion policy and recent vision-language-action models in real-world bimanual manipulation tasks. |
|
|
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Moo Jin Kim, Chelsea Finn, Percy Liang RSS 2025 project website / arXiv / code / models We introduce an Optimized Fine-Tuning (OFT) recipe for vision-language-action models that enables the 7B OpenVLA model to generate actions 25-50x faster and perform language-driven bimanual manipulation tasks on a new robot with enhanced success rates. OpenVLA-OFT achieves state-of-the-art 97.1% average success rate on the LIBERO simulation benchmark and also outperforms π0, RDT-1B, Diffusion Policy, and ACT in our real-world ALOHA robot experiments. |
|
|
CoT-VLA: Visual Chain-of-Thought Reasoning for Vision-Language-Action Models
Qingqing Zhao, Yao Lu, Moo Jin Kim, Zipeng Fu, Zhuoyang Zhang, Yecheng Wu, Max Li, Qianli Ma, Song Han, Chelsea Finn, Ankur Handa, Ming-Yu Liu, Donglai Xiang*, Gordon Wetzstein*, Tsung-Yi Lin* CVPR 2025 project website / arXiv * equal advising We introduce CoT-VLA, a vision-language-action model that incorporates explicit visual chain-of-thought reasoning by predicting future image frames auto-regressively as visual goals before generating action sequences. CoT-VLA outperforms prior state-of-the-art VLAs by 17% in real-world manipulation tasks and 6% in simulation benchmarks. |
|
|
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim*, Karl Pertsch*, Siddharth Karamcheti*, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, Chelsea Finn CoRL 2024 (Outstanding Paper Award Finalist: Top 6 papers) project website / arXiv / code / models * co-first authorship We introduce OpenVLA, a 7B-parameter open-source vision-language-action model (VLA), pretrained on 970k robot episodes from the Open X-Embodiment dataset. OpenVLA sets a new state of the art for generalist robot manipulation policies. It supports controlling multiple robots out of the box and can be quickly adapted to new robot setups via parameter-efficient fine-tuning. OpenVLA models, code, and training data are fully open-source. |
|
|
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Open X-Embodiment Collaboration, ... , Moo Jin Kim, ... IEEE ICRA 2024 (Best Conference Paper Award) project website / paper / blog post / data authors listed in alphabetical order; project led by Quan Vuong and Karl Pertsch; Stanford evaluations led by Moo Jin Kim and Max Du We introduce the Open X-Embodiment Dataset, the largest robot learning dataset to date with 1M+ real robot trajectories, spanning 22 robot embodiments. We train large, Transformer-based policies on the dataset (RT-1-X, RT-2-X) and show that co-training with our diverse dataset substantially improves performance. |
|
|
BridgeData V2: A Dataset for Robot Learning at Scale
Homer Walke, Kevin Black, Abraham Lee, Moo Jin Kim, Max Du, Chongyi Zheng, Tony Zhao, Philippe Hansen-Estruch, Quan Vuong, Andre He, Vivek Myers, Kuan Fang, Chelsea Finn, Sergey Levine CoRL 2023 project website / arXiv We introduce BridgeData V2, a large and diverse dataset of robotic manipulation behaviors designed to facilitate research on scalable robot learning. BridgeData V2 contains 60,096 trajectories collected across 24 environments on a publicly available low-cost robot. |
|
|
NeRF in the Palm of Your Hand: Corrective Augmentation for Robotics via Novel-View Synthesis
Allan Zhou*, Moo Jin Kim*, Lirui Wang, Pete Florence, Chelsea Finn CVPR 2023 project website / arXiv * co-first authorship We leverage neural radiance fields (NeRFs) to generate perturbed end-effector wrist camera viewpoints while simultaneously calculating corrective actions in order to improve absolute success rates of 6-DoF robotic grasping policies by 22.5% on average. |
|
|
Giving Robots a Hand: Learning Generalizable Manipulation with Eye-in-Hand Human Video Demonstrations
Moo Jin Kim, Jiajun Wu, Chelsea Finn NeurIPS Deep Reinforcement Learning Workshop 2022 project website / arXiv We augment narrow robotic imitation datasets with broad unlabeled human video demonstrations to greatly enhance the generalization of eye-in-hand visuomotor policies. Although a clear visual domain gap exists between human and robot data, our framework does not need to employ any explicit domain adaptation method and enables robots to generalize to both new environment configurations and new tasks that are unseen in the robot demonstration data. |
|
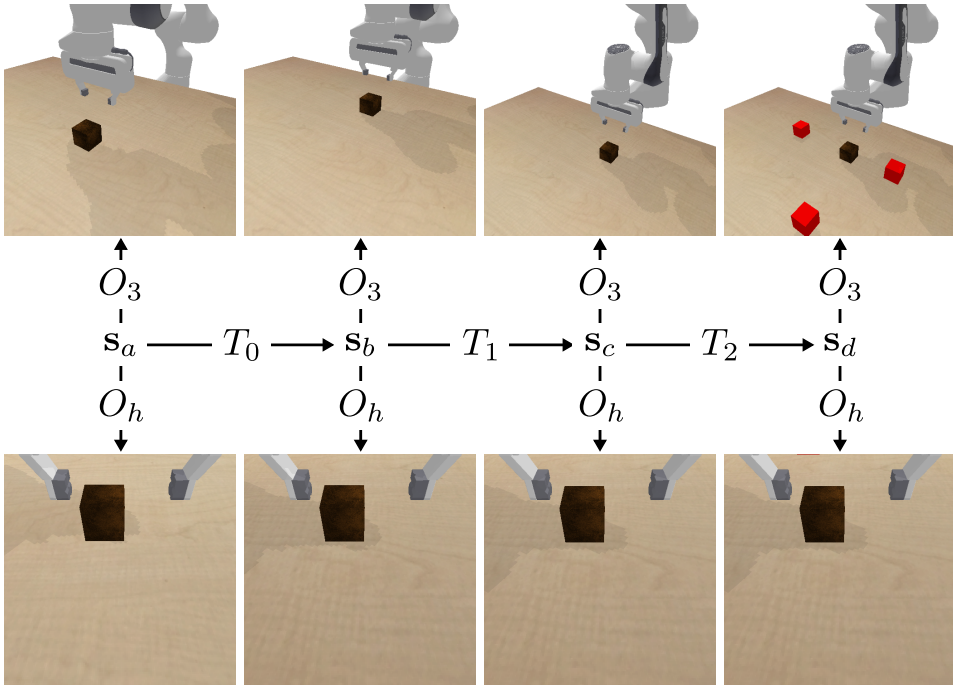
Vision-Based Manipulators Need to Also See from Their Hands
Kyle Hsu*, Moo Jin Kim*, Rafael Rafailov, Jiajun Wu, Chelsea Finn ICLR 2022 (Oral Presentation: Top 1.6% of submissions) project website / arXiv / code * co-first authorship; order determined by coin flip We conduct extensive experiments to show that utilizing a hand-centric (eye-in-hand) visual perspective consistently improves training efficiency and out-of-distribution generalization in vision-based robotic manipulation. These benefits hold across a variety of learning algorithms, experimental settings, and distribution shifts. When hand-centric observability is not sufficient, we propose a simple yet effective approach to incorporate a third-person information stream while regularizing it via a variational information bottleneck to prevent overfitting. |
Teaching/MentoringI enjoy teaching and mentoring students. In the past, I have served as:
|
Invited Talks & Media
|